Publications
Click here for abstract

ObjectMover: Generative Object Movement with Video Prior
Simple as it seems, moving an object to another location within an image is, in fact, a challenging image-editing task that requires re-harmonizing the lighting, adjusting the pose based on perspective, accurately filling occluded regions, and ensuring coherent synchronization of shadows and reflections while maintaining the object identity. In this paper, we present ObjectMover, a generative model that can perform object movement in highly challenging scenes. Our key insight is that we model this task as a sequence-to-sequence problem and fine-tune a video generation model to leverage their knowledge of consistent object generation across video frames. We show that with this approach, our model is able to adjust to complex real-world scenarios, handling extreme lighting harmonization and object effect movement. As large-scale data for object movement are unavailable, we construct a data generation pipeline using a modern game engine to synthesize high-quality data pairs. We further propose a multi-task learning strategy that enables training on real-world video data to improve the model generalization. Through extensive experiments, we demonstrate that ObjectMover achieves outstanding results and adapts well to real-world scenarios.
Generative Model
Image Editing
Video Generation
Feed-forward Model

TEXGen: a Generative Diffusion Model for Mesh Textures
While high-quality texture maps are essential for realistic 3D asset rendering, few studies have explored learning directly in the texture space, especially on large-scale datasets. In this work, we depart from the conventional approach of relying on pre-trained 2D diffusion models for test-time optimization of 3D textures. Instead, we focus on the fundamental problem of learning in the UV texture space itself. For the first time, we train a large diffusion model capable of directly generating high-resolution texture maps in a feed-forward manner. To facilitate efficient learning in high-resolution UV spaces, we propose a scalable network architecture that interleaves convolutions on UV maps with attention layers on point clouds. Leveraging this architectural design, we train a 700 million parameter diffusion model that can generate UV texture maps guided by text prompts and single-view images. Once trained, our model naturally supports various extended applications, including text-guided texture inpainting, sparse-view texture completion, and text-driven texture synthesis.
Generative Model
3D Vision
Feed-forward Model

Text-to-3D with Classifier Score Distillation
Text-to-3D generation has made remarkable progress recently, particularly with methods based on Score Distillation Sampling (SDS) that leverages pre-trained 2D diffusion models. While the usage of classifier-free guidance is well acknowledged to be crucial for successful optimization, it is considered an auxiliary trick rather than the most essential component. In this paper, we re-evaluate the role of classifier-free guidance in score distillation and discover a surprising finding, i.e., the guidance alone is enough for effective text-to-3D generation tasks. We name this method Classifier Score Distillation (CSD), which can be interpreted as using an implicit classification model for generation. This new perspective reveals new insights for understanding existing techniques. We validate the effectiveness of CSD across a variety of text-to-3D tasks including shape generation, texture synthesis, and shape editing, achieving results superior to those of state-of-the-art methods.
Generative Model
3D Vision
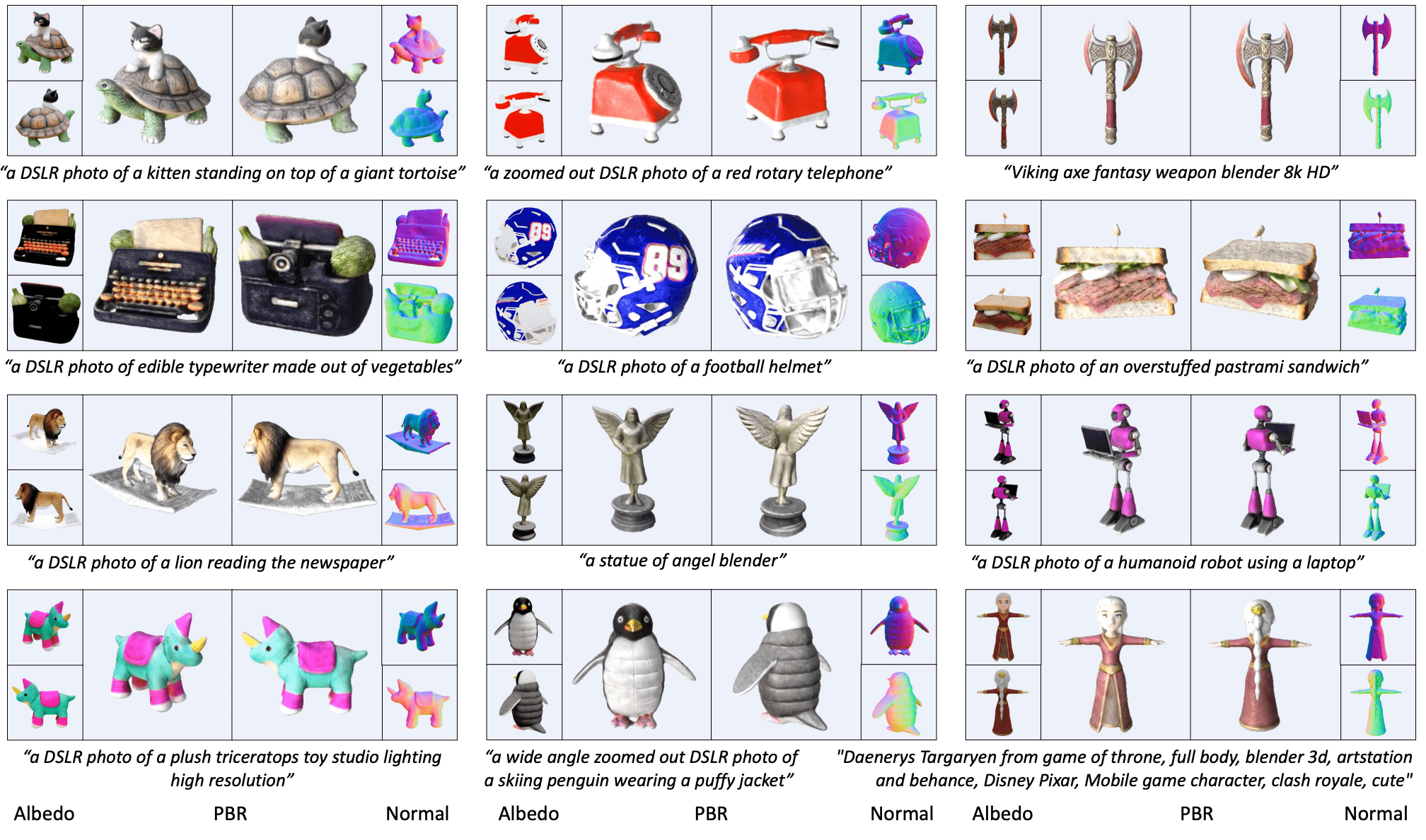
Unidream: Unifying diffusion priors for relightable text-to-3d generation
Recent advancements in text-to-3D generation technology have significantly advanced the conversion of textual descriptions into imaginative well-geometrical and finely textured 3D objects. Despite these developments, a prevalent limitation arises from the use of RGB data in diffusion or reconstruction models, which often results in models with inherent lighting and shadows effects that detract from their realism, thereby limiting their usability in applications that demand accurate relighting capabilities. To bridge this gap, we present UniDream, a text-to-3D generation framework by incorporating unified diffusion priors. Our approach consists of three main components: (1) a dual-phase training process to get albedo-normal aligned multi-view diffusion and reconstruction models, (2) a progressive generation procedure for geometry and albedo-textures based on Score Distillation Sample (SDS) using the trained reconstruction and diffusion models, and (3) an innovative application of SDS for finalizing PBR generation while keeping a fixed albedo based on Stable Diffusion model. Extensive evaluations demonstrate that UniDream surpasses existing methods in generating 3D objects with clearer albedo textures, smoother surfaces, enhanced realism, and superior relighting capabilities.
Generative Model
3D Vision

Image Inpainting via Iteratively Decoupled Probabilistic Modeling
Generative adversarial networks (GANs) have made great success in image inpainting yet still have difficulties tackling large missing regions. In contrast, iterative probabilistic algorithms, such as autoregressive and denoising diffusion models, have to be deployed with massive computing resources for decent effect. To achieve high-quality results with low computational cost, we present a novel pixel spread model (PSM) that iteratively employs decoupled probabilistic modeling, combining the optimization efficiency of GANs with the prediction tractability of probabilistic models. As a result, our model selectively spreads informative pixels throughout the image in a few iterations, largely enhancing the completion quality and efficiency. On multiple benchmarks, we achieve new state-of-the-art performance.
Generative Model
Image Synthesis

Texture Generation on 3D Meshes with Point-UV Diffusion
In this work, we focus on synthesizing high-quality textures on 3D meshes. We present Point-UV diffusion, a coarse-to-fine pipeline that marries the denoising diffusion model with UV mapping to generate 3D consistent and high-quality texture images in UV space. We start with introducing a point diffusion model to synthesize low-frequency texture components with our tailored style guidance to tackle the biased color distribution. The derived coarse texture offers global consistency and serves as a condition for the subsequent UV diffusion stage, aiding in regularizing the model to generate a 3D consistent UV texture image. Then, a UV diffusion model with hybrid conditions is developed to enhance the texture fidelity in the 2D UV space. Our method can process meshes of any genus, generating diversified, geometry-compatible, and high-fidelity textures.
Generative Model
3D Vision
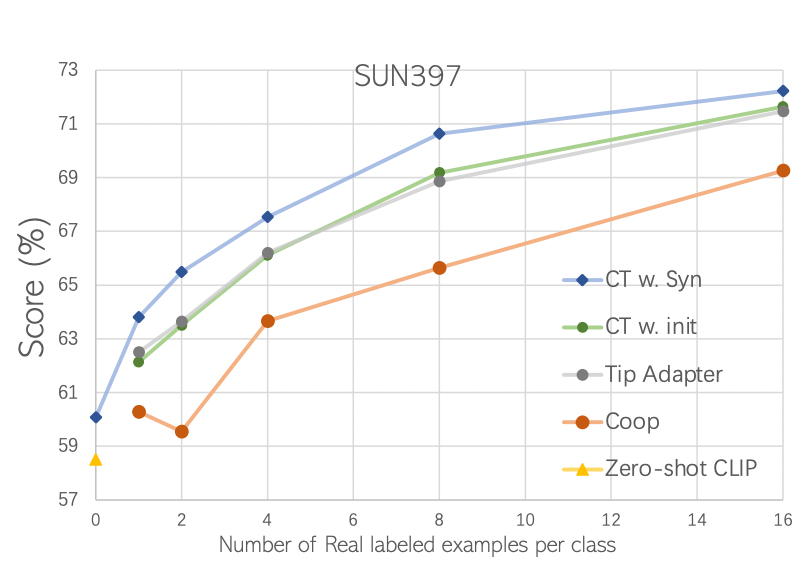
Is synthetic data from generative models ready for image recognition?
Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and fewshot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks.
Generative Model
Synthetic Data

Hybrid neural rendering for large-scale scenes with motion blur
Rendering novel view images is highly desirable for many applications. Despite recent progress, it remains challenging to render high-fidelity and view-consistent novel views of large-scale scenes from in-the-wild images with inevitable artifacts (e.g., motion blur). To this end, we develop a hybrid neural rendering model that makes image-based representation and neural 3D representation join forces to render high-quality, view-consistent images. Besides, images captured in the wild inevitably contain artifacts, such as motion blur, which deteriorates the quality of rendered images. Accordingly, we propose strategies to simulate blur effects on the rendered images to mitigate the negative influence of blurriness images and reduce their importance during training based on precomputed quality-aware weights. Extensive experiments on real and synthetic data demonstrate our model surpasses state-of-the-art point-based methods for novel view synthesis.
3D Vision

Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoireing
With the rapid development of mobile devices, modern widely-used mobile phones typically allow users to capture 4K resolution (i.e., ultra-high-definition) images. However, for image demoireing, a challenging task in low-level vision, existing works are generally carried out on low-resolution or synthetic images. Hence, the effectiveness of these methods on 4K resolution images is still unknown. In this paper, we explore moire pattern removal for ultra-high-definition images. To this end, we propose the first ultra-high-definition demoireing dataset (UHDM), which contains 5,000 real-world 4K resolution image pairs, and conduct a benchmark study on current state-of-the-art methods. Further, we present an efficient baseline model ESDNet for tackling 4K moire images, wherein we build a semantic-aligned scale-aware module to address the scale variation of moire patterns. Extensive experiments manifest the effectiveness of our approach, which outperforms state-of-the-art methods by a large margin while being much more lightweight.
Low-level Vision

Video Demoireing with Relation-based Temporal Consistency
Moire patterns, appearing as color distortions, severely degrade the image and video qualities when filming a screen with digital cameras. Considering the increasing demands for capturing videos, we study how to remove such undesirable moire patterns in videos, namely video demoireing. To this end, we introduce the first hand-held video demoireing dataset with a dedicated data collection pipeline to ensure spatial and temporal alignments of captured data. Further, a baseline video demoireing model with implicit feature space alignment and selective feature aggregation is developed to leverage complementary information from nearby frames to improve frame-level video demoireing. More importantly, we propose a relation-based temporal consistency loss to encourage the model to learn temporal consistency priors directly from ground-truth reference videos, which facilitates producing temporally consistent predictions and effectively maintains frame-level qualities. Extensive experiments manifest the superiority of our model.
Low-level Vision
High-dimensional anticounterfeiting nanodiamonds authenticated with deep metric learning
Physical unclonable function labels have emerged as a promising candidate for achieving unbreakable anticounterfeiting. Despite their significant progress, two challenges for developing practical physical unclonable function systems remain, namely 1) fairly few high-dimensional encoded labels with excellent material properties, and 2) existing authentication methods with poor noise tolerance or inapplicability to unseen labels. Herein, we employ the linear polarization modulation of randomly distributed fluorescent nanodiamonds to demonstrate, for the first time, three-dimensional encoding for diamond-based labels. Briefly, our three-dimensional encoding scheme provides digitized images with an encoding capacity of 10^9771 and high distinguishability under a short readout time of 7.5 s. The high photostability and inertness of fluorescent nanodiamonds endow our labels with high reproducibility and long-term stability. To address the second challenge, we employ a deep metric learning algorithm to develop an authentication methodology that computes the similarity of deep features of digitized images, exhibiting a better noise tolerance than the classical point-by-point comparison method. Meanwhile, it overcomes the key limitation of existing artificial intelligence-driven classification-based methods, i.e., inapplicability to unseen labels. Considering the high performance of both fluorescent nanodiamonds labels and deep metric learning authentication, our work provides the basis for developing practical physical unclonable function anticounterfeiting systems.
AI4Science